개요
LLM과 같은 AI 모델은 수조 개의 파라미터를 포함하며, 이를 학습시키기 위한 막대한 데이터와 연산 능력을 요구합니다. 단일 GPU로 이러한 작업을 처리하기에는 메모리와 계산 능력이 부족합니다.
분산 학습은 대규모 데이터와 복잡한 모델을 처리하기 위해 여러 GPU에 학습 작업을 나누어 수행하는 기술입니다. Model Parallelism과 Data Parallelism을 통해 이러한 문제를 해결하며, 네트워크 성능과 알고리즘 최적화를 통해 효율성을 높입니다. 결국 학습 속도를 높이고, 메모리 한계를 극복하며, 대규모 모델을 효율적으로 학습시킵니다.
주요 개념과 방식은 아래와 같습니다.
- 작업 분할: Model Parallelism, Data Parallelism
- 파라미터 동기화: 동기적 동기화, 비동기적 동기화
- 그래디언트 취합: AllReduce, Ring-AllReduce
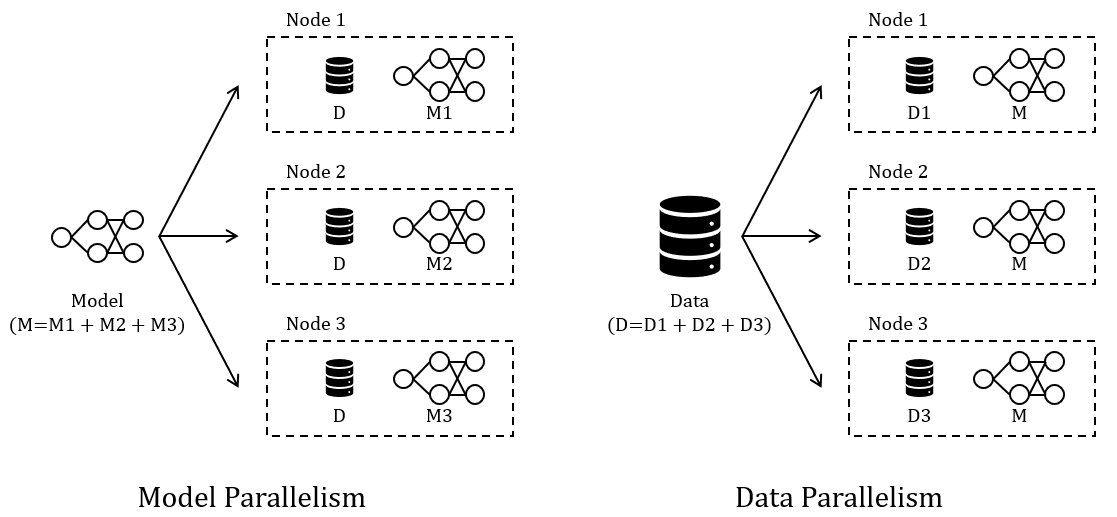
작업 분할 방식
1. Model Parallelism
모델 크기가 단일 GPU 메모리를 초과할 때, 모델을 여러 GPU에 분할하여 레이어 또는 텐서 단위로 배치합니다. 모델을 분할하여 여러 GPU에 복제하고, 각기 다른 데이터 샤드를 사용해 병렬로 학습합니다. 이후 그래디언트를 동기화하여 모델 파라미터를 업데이트합니다.
2. Data Parallelism
단일 GPU가 처리하기에는 데이터의 크기가 너무 커서 학습 시간이 과도하게 길어질 경우 사용됩니다. 데이터를 여러 GPU로 나누어 병렬로 처리함으로써 학습 시간을 단축합니다.
파라미터 동기화 방식
1. 동기적 동기화(Synchronous Replication)
모든 노드가 그래디언트 계산을 완료한 후 평균값을 계산해 파라미터를 업데이트합니다. 수렴 속도가 빠르지만, 느린 노드가 전체 학습 속도를 제한할 수 있습니다.
2. 비동기적 동기화(Asynchronous Replication)
각 노드가 그래디언트를 계산하는 즉시 파라미터를 업데이트합니다. 속도는 빠르지만, 파라미터 일관성이 떨어질 수 있습니다.

그래디언트 취합 방식
그래디언트 취합은 여러 GPU 또는 노드에서 계산된 그래디언트를 통합해 모델 파라미터를 업데이트하는 과정입니다.
1. AllReduce
모든 GPU에서 계산된 그래디언트를 취합한 뒤 다시 분배합니다. 단순하지만 네트워크 병목이 발생할 수 있습니다.
2. Ring-AllReduce
모든 GPU를 링 형태로 연결하여 그래디언트를 순차적으로 전달하고 취합하는 방식입니다. 각 GPU는 자신의 그래디언트를 다음 GPU로 전달하며, 최종적으로 모든 GPU에 취합된 그래디언트가 공유됩니다. 네트워크 부하를 줄이고 확장성을 높입니다.

'AI & GPU' 카테고리의 다른 글
| Tensor Parallelism과 Pipeline Parallelism (0) | 2025.04.20 |
|---|---|
| MCP (0) | 2025.04.20 |
| NVIDIA Triton Server (0) | 2025.04.11 |
| 자연어처리 - 인코딩 (0) | 2025.04.04 |
| FLOPS (0) | 2025.04.04 |