개요
인코딩(Encoding)은 자연어처리에서 텍스트를 기계가 이해할 수 있는 숫자 형태로 변환하는 과정을 의미합니다. 기계는 텍스트보다 숫자를 더 잘 처리하기 때문에, 숫자로 변환하는 것은 자연어처리의 필수적인 전처리 단계입니다.
원-핫 인코딩
원-핫 인코딩(One-Hot Encoding)은 문서에 등장하는 단어를 이진 벡터로 변환하여 컴퓨터가 처리할 수 있도록 합니다.
구현이 간단하여 데이터의 범주적 특성을 명확히 표현할 수 있습니다. 또한, 범주형 데이터가 가지는 순서나 크기 정보를 제거하여 모델이 이를 잘못 학습하지 않도록 합니다.
다만, 원-핫 인코딩은 단순히 특정 위치에만 1을 부여하므로 단어 간의 유사성을 반영하지 못합니다.
아래 이미지는 원-핫 인코딩 후 인코딩 값을 확인하는 파이썬 코드입니다.

워드 임베딩(Word Embedding)
워드 임베딩(Word Embedding)은 자연어처리에서 단어를 고정된 크기의 밀집 벡터(Dense Vector)로 표현하는 기술입니다. 벡터는 단어 간의 의미적 관계를 반영하며, 단어를 수치화하여 기계가 이해할 수 있도록 돕습니다. 워드 임베딩은 단순한 숫자 변환을 넘어, 단어의 의미와 문맥적 정보를 포함하는 강력한 표현 방식입니다.
원-핫 인코딩은 구현이 간단하지만 단어 간의 관계를 반영하지 못하고 텍스트 크기에 따라 차원이 커지는 문제가 있습니다. 반면 워드 임베딩은 학습을 통해 단어 간의 의미적 관계를 반영하며 차원이 고정되어 효율적입니다. 따라서 복잡한 자연어 처리 작업에서는 워드 임베딩이 더 적합합니다.
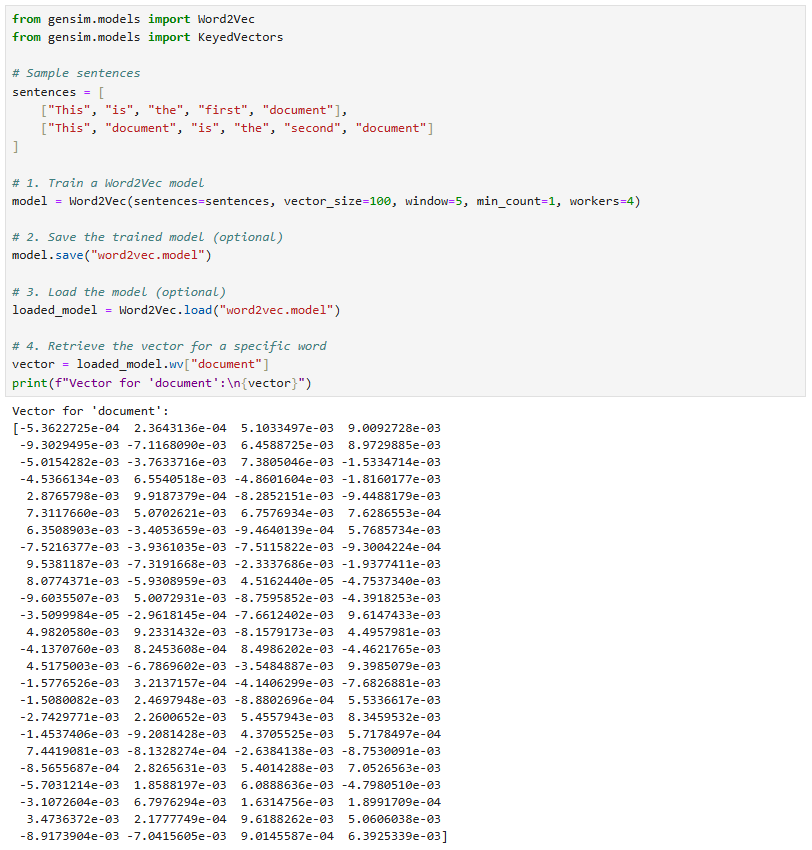
아래 이미지는 Word2Vec으로 워드 임베딩 후, 'document'의 임베딩 값을 확인하는 파이썬 코드입니다.
단어 빈도
단어 빈도(Term Frequency, TF)는 특정 단어가 한 문서 내에서 얼마나 자주 등장하는지를 측정하는 지표입니다. 텍스트 특성을 파악하고, 단어의 중요도를 평가하기 위해 사용됩니다.
단어 빈도는 다음과 같은 수식으로 계산됩니다.

아래 이미지는 단어 빈도를 확인하는 파이썬 코드입니다.

역문서 빈도(Inverse Document Frequency, IDF)
역문서 빈도(Inverse Document Frequency, IDF)는 특정 단어가 문서 집합 전체에서 얼마나 드물게 등장하는지를 측정합니다. 이는 단어의 중요도를 평가하기 위해 사용되며, 흔하게 등장하는 단어보다는 특정 문서에서만 자주 등장하는 단어에 더 높은 가중치를 부여합니다.
- 높은 IDF 값: 적은 문서에서 등장. 중요도가 높은 것으로 간주됨
- 낮은 IDF 값: 많은 문서에서 등장. 중요도가 낮은 것으로 간주됨(예: "그리고", "하지만"과 같은 불용어)
역문서 빈도는 다음과 같은 수식으로 계산됩니다.

아래 이미지는 역문서 빈도를 확인하는 파이썬 코드입니다.

TF-IDF
TF-IDF(Term Frequency - Inverse Document Frequency)는 단어 빈도와 역문서 빈도를 곱한 가중치로, 문서에서 특정 단어의 중요도를 나타내는 지표입니다.
TF-IDF는 다음과 같은 수식으로 계산됩니다.

아래 이미지는 TF-IDF 값을 확인하는 파이썬 코드입니다.

'AI & GPU' 카테고리의 다른 글
| AI 학습에서의 분산 학습 (0) | 2025.04.13 |
|---|---|
| NVIDIA Triton Server (0) | 2025.04.11 |
| FLOPS (0) | 2025.04.04 |
| NCCL (0) | 2025.04.02 |
| 머신러닝에서 요구하는 선형대수학 02 - 벡터 연산 (0) | 2025.03.29 |