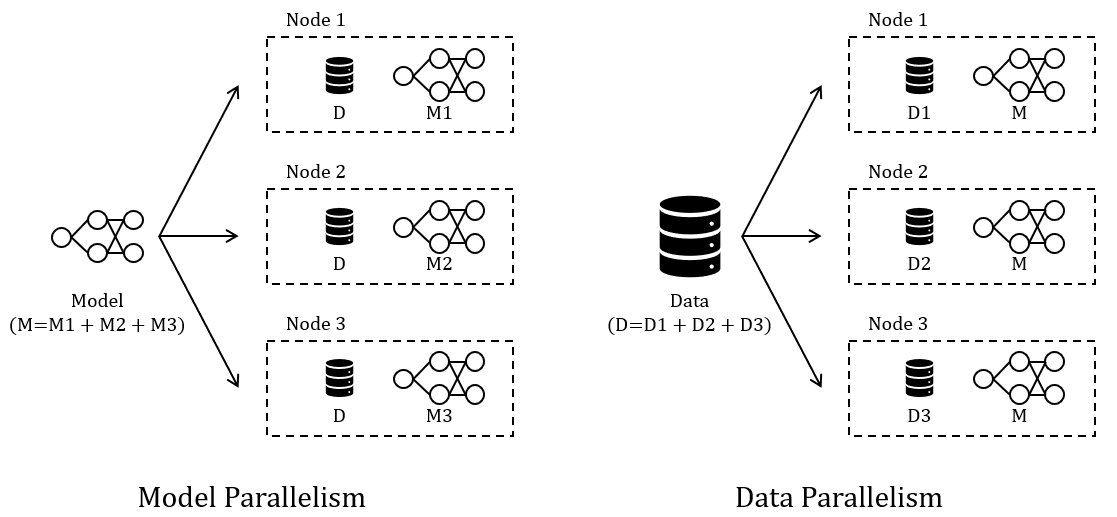
개요LLM과 같은 AI 모델은 수조 개의 파라미터를 포함하며, 이를 학습시키기 위한 막대한 데이터와 연산 능력을 요구합니다. 단일 GPU로 이러한 작업을 처리하기에는 메모리와 계산 능력이 부족합니다. 분산 학습은 대규모 데이터와 복잡한 모델을 처리하기 위해 여러 GPU에 학습 작업을 나누어 수행하는 기술입니다. Model Parallelism과 Data Parallelism을 통해 이러한 문제를 해결하며, 네트워크 성능과 알고리즘 최적화를 통해 효율성을 높입니다. 결국 학습 속도를 높이고, 메모리 한계를 극복하며, 대규모 모델을 효율적으로 학습시킵니다. 주요 개념과 방식은 아래와 같습니다.작업 분할: Model Parallelism, Data Parallelism파라미터 동기화: 동기적 동기화, 비동기적..