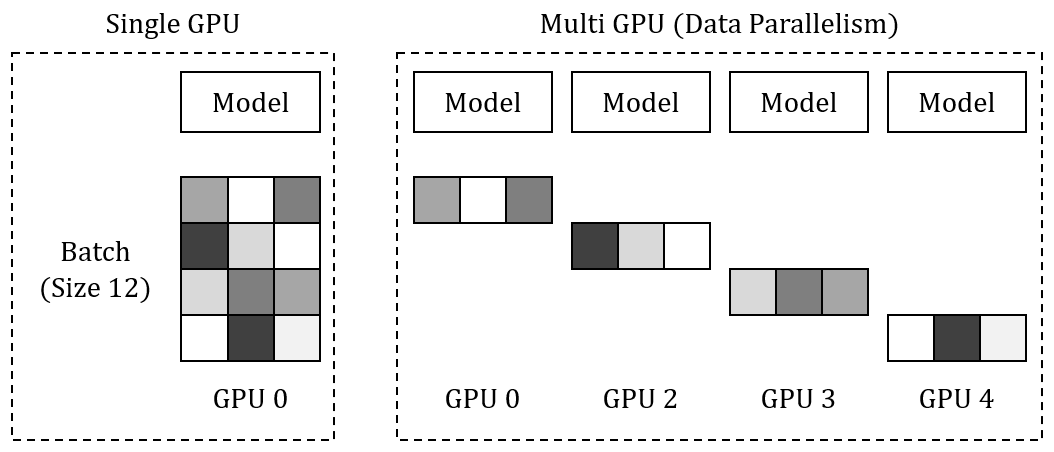
개요Tensor Parallelism과 Pipeline Parallelism은 대규모 딥러닝 모델 학습을 위한 상호보완적 병렬화 전략으로, 각각 다른 차원에서 모델을 분할해 처리합니다.Tensor Parallelism (TP)Pipeline Parallelism (PP)대형 텐서 연산 가속화대규모 모델의 메모리 분산텐서/행렬 연산 (레이어 내부)모델 레이어 (레이어 간)레이어 내부 분할 병렬화레이어 간 분할 병렬화 Tensor Parallelism 모델을 여러 GPU에 분산해 학습하는 기법으로, 모델의 텐서(행렬)를 분할해 병렬 처리함으로써 단일 GPU의 메모리 한계를 극복하고 계산 효율성을 높입니다. Weight Matrix를 여러 GPU로 분산해 연산을 한 후 그 결과값을 합치는(Concatenate..