개요
클라우드 환경에서 실패를 대비한 설계(Design for Failure)란, 시스템이 실패하거나 장애가 발생했을 때도 서비스가 지속적으로 운영될 수 있도록 아키텍처를 설계하는 원칙입니다. 이는 클라우드 컴퓨팅의 핵심 개념 중 하나로, 특히 고가용성과 복원력을 보장하기 위해 중요합니다.
고가용성(High Availability, HA)는 IT 시스템이 장애나 다운타임을 최소화하여 거의 100%에 가까운 시간 동안 지속적으로 정상 운영될 수 있는 능력을 의미합니다. 이는 서비스 중단으로 인한 사용자 불편과 기업의 손실을 줄이기 위해 중요한 설계 원칙입니다.
고가용성을 구현하기 위한 전략은 다음과 같습니다.
- 로드 밸런싱
- 자동화된 장애 감지 및 복구
- 데이터 복제 및 백업
- 지리적 중복 배치 (Disaster Recovery)
로드 밸런싱
로드 밸런서 자체가 단일 장애 지점(SPOF)이 되지 않도록 이중화 구성합니다.
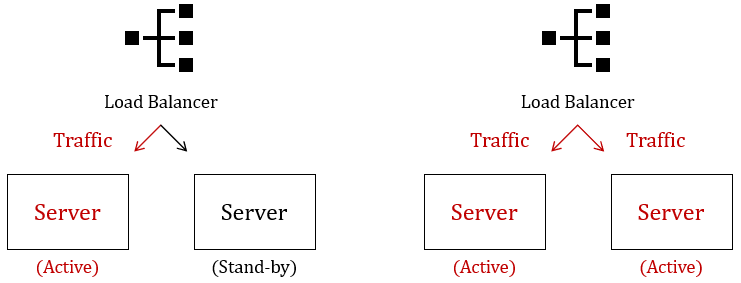
- Active-Standby 구성: 하나의 로드 밸런서는 활성 상태로 트래픽을 처리하고, 다른 로드 밸런서는 대기 상태로 있다가 활성 로드 밸런서가 장애를 겪으면 자동으로 트래픽을 처리합니다.
- Active-Active 구성: 여러 로드 밸런서가 동시에 활성 상태로 트래픽을 처리하며, 하나의 노드가 장애를 겪으면 나머지 노드들이 트래픽을 분담합니다.
트래픽을 분산하는 적합한 알고리즘을 선택합니다.
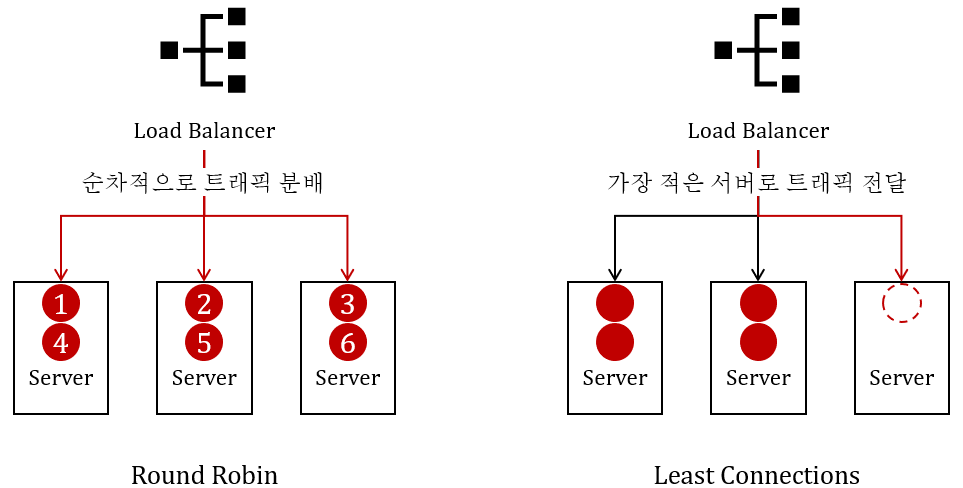
- 라운드 로빈(Round Robin): 순차적으로 서버에 트래픽을 분배하는 방식으로 간단하고 균등한 분배에 적합합니다.
- 최소 연결(Least Connections): 현재 연결 수가 가장 적은 서버로 트래픽을 보내는 방식으로, 실시간 부하를 고려합니다.
- 가중 라운드 로빈(Weighted Round Robin): 서버의 성능에 따라 가중치를 설정하여 더 많은 트래픽을 특정 서버로 보냅니다.
- IP 해시(IP Hash): 클라이언트 IP를 기반으로 특정 서버에 트래픽을 고정적으로 할당합니다.
자동화된 장애 감지 및 복구
장애 감지 시스템 구축하여 시스템 상태를 실시간으로 모니터링합니다.
- 헬스 체크(Health Check): 서버, 네트워크, 데이터베이스 등의 상태를 주기적으로 점검합니다.
- 사용자 정의 스크립트 활용: Bash 등으로 작성된 스크립트를 통해 복잡한 장애 시나리오를 감지합니다.
자동화된 복구(Failover) 메커니즘을 통해, 문제 발생시 자동으로 복구하거나 대체 시스템으로 전환합니다.
- Active-Standby 구성: 기본 노드에 장애 발생 시 대기 노드로 트래픽을 자동 전환합니다.
- Active-Active 구성: 여러 노드가 동시에 서비스하며, 장애 노드는 로드 밸런서에서 제외됩니다.
데이터 복제 및 백업
데이터 손실을 방지하기 위해 데이터를 실시간으로 복제하거나 정기적으로 백업합니다.
- 동기식 복제(Synchronous Replication): 데이터가 동시에 기본(Primary) 및 보조(Secondary) 서버에 기록됩니다.
- 비동기식 복제(Asynchronous Replication): 데이터가 기본 서버에 먼저 기록된 후 일정 시간 간격으로 보조 서버로 전송됩니다.
구성에 적합한 복제 토폴로지를 구성합니다.
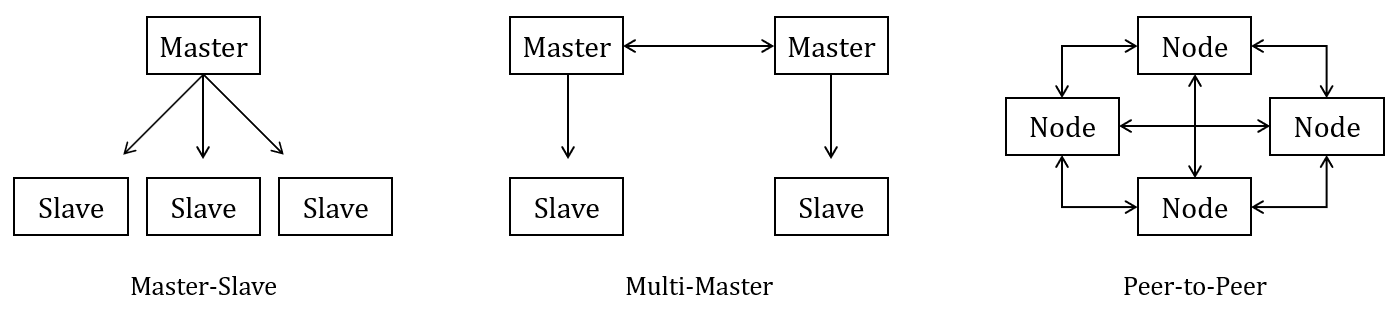
- 마스터-슬레이브(Master-Slave): 한 서버가 데이터를 관리하고 다른 서버가 복사본을 유지합니다.
- 멀티-마스터(Multi-Master): 여러 서버에서 읽기와 쓰기가 가능하며, 데이터 충돌 방지가 필요합니다.
- 피어-투-피어(Peer-to-Peer): 모든 노드가 동등한 권한을 가지며 데이터를 공유합니다.
지리적 중복 배치 (Disaster Recovery)
지리적 중복 배치(Disaster Recovery, DR)는 여러 지역에 서비스를 배포하여 특정 지역에서 문제가 발생하더라도 서비스 연속성을 유지합니다. 자연재해, 네트워크 장애 등 광범위한 장애로부터 비즈니스 연속성을 보호하는 데 필수적입니다.
- Active-Passive 구성: 주 데이터 센터(Active)가 트래픽을 처리하고, 보조 데이터 센터(Passive)는 대기 상태로 유지됩니다.
- Active-Active 구성: 여러 데이터 센터가 동시에 트래픽을 처리하며, 장애 시 자동으로 전환됩니다.

결론
장애가 반드시 발생한다는 것은 시스템을 구성하는 모든 구성요소는 언젠가는 반드시 고장날 것임을 의미합니다. 언제 발생 될 지 모르는 장애에 대해 대비책을 설계해 놓아야 신뢰성이 높은 시스템을 설계 할 수 있습니다.